
As of our 20.1 release, CockroachDB supports online primary key changes. This means that it is now possible to change the primary key of a table while performing read and write operations on the table. Online primary key changes make it easier to transition an application from being single-region to multi-region, or to iterate on the schema of an application with no down time. Let’s dive into the technical challenges behind this feature, and our approach to solving them. As part of the deep dive, let’s review how data is stored in CockroachDB, and how online schema changes work in CockroachDB.
```Data Layout in CockroachDB
In many database systems, a primary key is just another index on a table, with extra NOT NULL and unique constraints. Changing the primary key of a table usually just involves changing what index is denoted as the primary key. In CockroachDB, the primary key is special -- all the data for a table is stored on disk as part of the primary key.
In order to see how and why CockroachDB stores all data in the primary key, let’s dive into how data storage works in the database. The SQL layer of CockroachDB is built on top of a distributed, transactionally consistent key-value store (for the rest of the blog post we’ll refer to key-value as KV). The SQL system in CockroachDB uses this KV map to store SQL table data and indexes. Let's take a look at what a table and some corresponding data would look like in CockroachDB. Consider the following table and data:
CREATE TABLE t (
x INT,
y INT,
z INT,
w STRING,
PRIMARY KEY (x, y)
);
In CockroachDB, row entries in the table are stored as KV pairs. The primary key columns form the key, and the remaining columns form the value. A row of data would be stored something like this:
| Row | Key | Value |
| (1, 2, 3, ‘hello’) | /t/primary/1/2/ | (3, ‘hello’) |
In order to change the primary key of a table, we have to rewrite the table data so that the KV pairs are organized according to the new primary key columns. Secondary indexes are stored in a similar way as the primary key -- the indexed columns form the key, and the value is generally empty. This encoding strategy limits data duplication, as only the indexed columns are duplicated. If we created an index using CREATE INDEX i ON t (y, z) the KV’s for index i would look something like:
| Row | Key | Value |
| (1, 2, 3, ‘hello’) | /t/i/2/3/ | () |
However, if we use a secondary index in a query to find a particular row, we need to be able to find the rest of the row’s data from the secondary index entry. In order to “point back” to the primary index entry for a row, all secondary indexes need to implicitly contain all of the primary key columns. After including the remaining primary key columns, our index entries end up looking like:
| Row | Key | Value |
| (1, 2, 3, ‘hello’) | /t/i/2/3/(1:x) | () |
So our KV’s for the primary index and secondary index i together look like:
| Row | PK Key | PK Value | Index Key | Index Value |
| (1, 2, 3, ‘hello’) | /t/primary/1/2/ | (3, ‘hello’) | /t/i/2/3/(1:x) | () |
For more details on CockroachDB’s architecture take a look at our docs or an architecture overview webinar.
This strategy for encoding table data means that there is an implicit dependency between the indexes of a table and the table’s primary index. If we want to change the primary index of a table, we need to change it and all the indexes that depend on it. For example, if we changed the primary key of t to be w we’d also need to update i to contain w and not x The difficult part of performing this schema change is ensuring that users of the table only observe the table in a consistent state either before or after the primary key has changed, and that all operations on the table during the primary key change return correct data.
Let’s examine how online schema changes work in CockroachDB, and how we can build support for primary key changes on top of this infrastructure.
Online Schema Changes
To perform a primary key change in CockroachDB, the primary key and some new indexes must be rebuilt. To do this, we can take advantage of the existing online schema change infrastructure, so let’s dive into how it works.
When adding a new schema element to a table (like an index), CockroachDB won’t just add the element into the metadata of the table. In a distributed system, doing so could result in data inconsistency between nodes in the system. Talks of data inconsistency may seem out of place as CockroachDB is a serializable and strongly consistent database. However, CockroachDB needs to cache table metadata in order to be performant. Without caching this metadata, a node would need to perform a KV operation every time it needed to access information about a table! As with any cache, it needs to be invalidated when the cached data becomes stale. With this in mind, the data inconsistency mentioned above could happen in the following way:
- Node 1 adds an index
ito a tabletand starts to build it. - Node 2 inserts value
vintotbefore its metadata fortis invalidated. Since node 2 has no idea thatiexists, it doesn’t make an entry forvini. - Node 1 attempts to read
iafter it is done building and cannot findv!
In order to safely perform schema changes, CockroachDB progresses schema elements through a series of states, where the new element is finally added at the end of this series. A key part of this state machine is that at any point during the schema change, all nodes are at most 1 state apart in the state machine. If this state machine is an ordered set of states S then nodes at any point in the schema change must have either state S\_i or S\_{i+1} In CockroachDB, these states are associated with different capabilities on the schema object. The capabilities of each state describe which operations on the table will also be applied to the in-progress schema element. These states are:
- Delete Only (referred to as D). Schema objects in this state service only deletion operations.
- Delete and Write Only (referred to as DW). Schema objects in this state service only write and deletion operations.
- All (referred to as R). Schema objects in this state are now “public” and are accessible for all operations: reads, writes and deletions.
To begin an index creation, CockroachDB adds the index to the table’s metadata in state D which starts the schema change state machine. Once all nodes in the cluster have agreed on the index’s state, the index progresses into the DW state. CockroachDB starts to backfill existing data into the index in the DW state, and forwards incoming writes to the index. Upon completion of the backfill and all nodes agreeing on the state DW, the index is moved to state R. Once every node agrees on state R the schema change is complete.
The procedure to drop a schema element is the same process as adding a schema element, but done in reverse. Instead of incrementally adding capabilities to a schema element, we incrementally remove capabilities until the element has no capabilities. An object with no capabilities is safe to drop.
To get some intuition about how this series of states ensures that new schema elements have consistent data, we can examine a few cases during the process of adding an index.
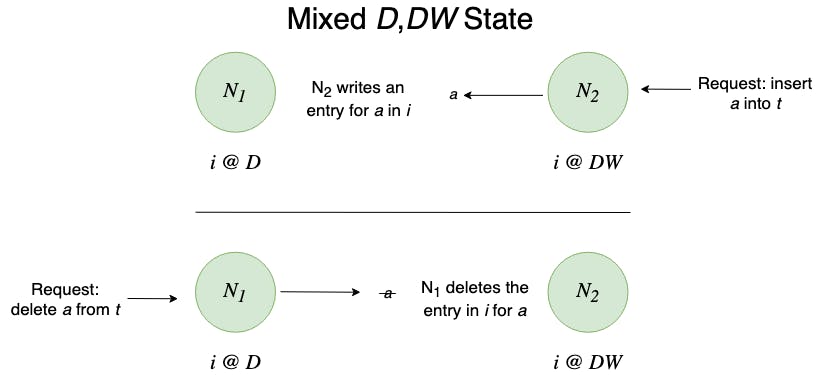
Example 1: Mixed D and DW states.
Consider two nodes N_1 and N_2 where N_1holds an index i of table t in state D and the N_2 holds i in state DW. The state machine in this case ensures that there are no spurious index entries. All write requests sent to N_2will create an entry in the i for the written data. Because of the capabilities assigned to N_1 all delete requests sent to N_1 will also delete the index entry, ensuring that i is not left with a dangling index entry.
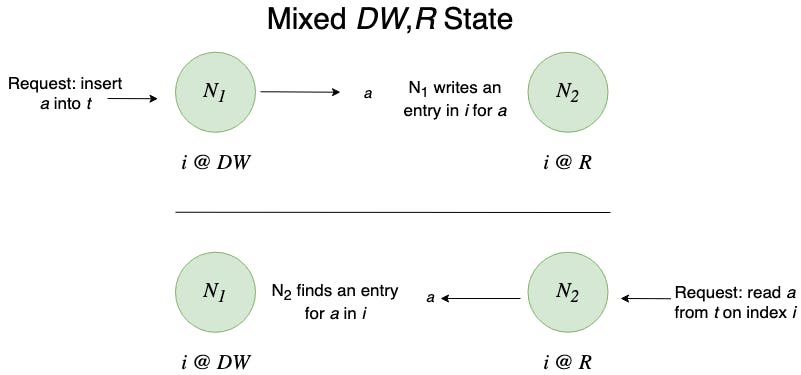
Example 2: Mixed DW and R states.
Consider two nodes N_1 and N_2 where N_1 holds an index i of table t in state DW and N_2 holds i in state R In this case, the state machine ensures that there are no missing index entries for reads. Because all writes to t on N_1 will be written to i reads on i from N_2 will find the written values.
For a different perspective on online schema changes, and some extra topics like schema caching and node failure recovery during schema changes, take a look at our previous blog post on online schema changes!
Primary Key Changes
The schema change system in CockroachDB can support adding and dropping schema elements, but performing an online primary key change requires doing more. In particular, we have all the requirements of an online schema change, but also need to ensure that all nodes in the system either view the target table as completely before or completely after the primary key change. A node must not see that a table has the new primary key, and no updated indexes, or vice versa. Additionally, the whole CockroachDB cluster needs to operate correctly if some nodes don’t know that the primary key has been changed.
Looking closely at what goes into a primary key change, there are three distinct steps that need to be performed:
- We need to build the new primary index along with the new versions of dependent indexes.
- Once the new primary key and indexes are ready to be used, we need to swap out what is designated as the primary key, and update all indexes to the new index versions.
- We need to drop the old primary key and indexes.
An important point to notice is that the end of step 1 must be performed along with step 2 and the beginning of step 3. Specifically, as our new indexes are promoted into a readable state, the old indexes need to be demoted out of the readable state. Doing this sequence of steps as an atomic operation will ensure that a single node sees a consistent and valid view of the table -- either before or after the swap. The example below details what requests to different nodes view as the primary key of the table during this process, where old and new are the old and new primary keys of the table.

As the previous diagram shows, there are states where some nodes view the primary key of the table before the swap, and some nodes will view it after. Let’s look at how all operations on the database will return consistent data in this mixed primary key state.
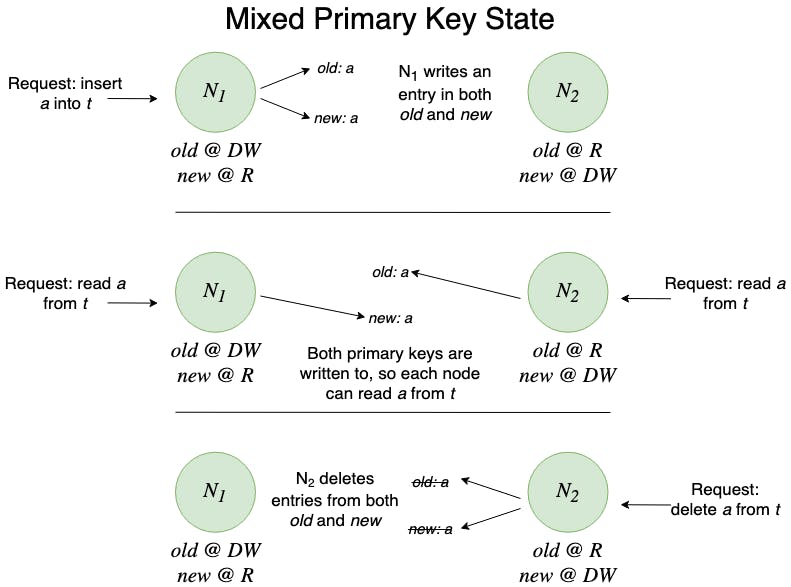
For simplicity, consider a primary key change where only a new primary key is built. Consider two nodes N_1 and N_2 as well as old and new primary keys on a table t old and new.
After the swap in step 2 commits, some nodes will view old demoted to state DW and new promoted to state R and other nodes will view old in state R and new waiting to be promoted to R. Assume that N_1 views the former, and N_2 views the latter.
This new state configuration ensures both of the properties from earlier -- no dangling index entries, and no missed index entries. All mutation operations that either node issues will also be applied to whichever index the node thinks is not the current primary index. This ensures that all written values can be read by either node, and that deletes from either node won’t leave any dangling entries.
This is a neat extension of the properties discussed in the section about general online schema changes. A schema change progresses safely if the only states of a schema element present in a cluster are 1 state “apart” from each other in the state machine. This property is maintained by the swapping operation:
- The new primary key transitions from DW to R.
- The old primary key transitions from R to DW.
Because both the schema elements transition to a state 1 step away in the state machine, we can combine the guarantees on both transitions to ensure the resulting schema change is safe!
Interaction With Existing CockroachDB Features
Implementing online primary key changes required some leg work to play nicely with a variety of features in CockroachDB. I’d like to share some of the more interesting feature integrations that went on during development of online primary key changes.
- Column Families. In CockroachDB, only primary indexes respected KV level separation described by the column families on a table. The process for primary key changes involves building a secondary index like a primary index, and then switching which index the table thinks is “primary”. This process involved teaching secondary indexes in CockroachDB how to respect column families, as well ensuring that secondary indexes without families in existing CockroachDB clusters are still usable after a version upgrade.
- Foreign Keys. Our representation of foreign key metadata had to be changed to ensure that nodes could find valid indexes to use for foreign key constraint validation in the mixed index/primary key version state detailed above. This work involved tricky reasoning about metadata representations in mixed version clusters.
- Other Schema Changes. The ability to change the primary key of a table may have opened up ways to perform other bulk operations within CockroachDB more efficiently. For example, adding or dropping columns could be viewed as creating a new primary key with the desired new column. Structuring bulk operations this way could lead to faster implementations that interact better with the underlying storage layer of CockroachDB.
Conclusion
Even on a serializable and consistent KV store, table metadata caching makes performing online schema changes difficult. Changing the primary key of a table is particularly challenging due to its nature as the primary data source of the table, as well as the implicit dependency that other indexes on the table have on it. Our approach was to extend the state machine based approach used for standard online schema changes with an atomic "swapping" operation and show that guarantees about correctness are maintained.
If building distributed SQL engines is your fancy, we’re hiring! Take a look at our open positions here.


